みなさんお久しぶりです。
今日は検索ワードを見ていて標準化を戻したい方々がいるようなのでアンサーをしてみたいと思います。
また、標準化を元に戻す場面ってありますか?という話もします。
それでは早速、コードを書いておきます。
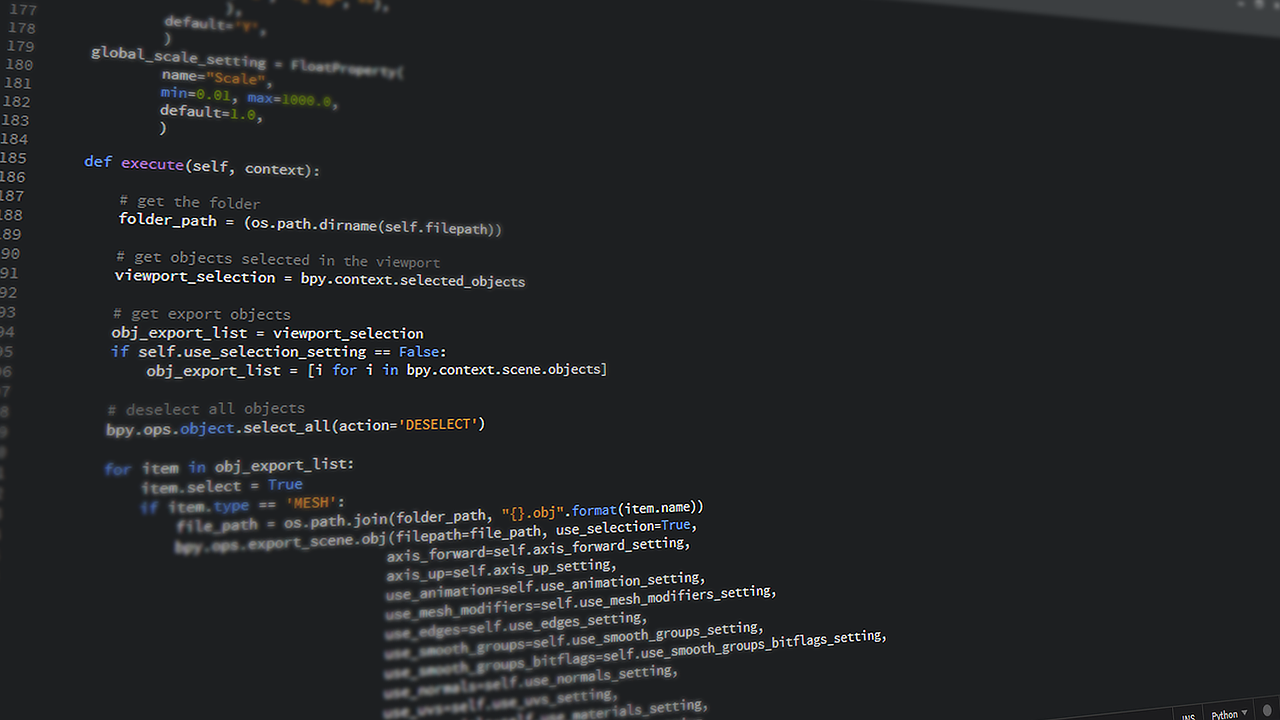
Pythonコード
導入(読み飛ばしてOK)
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
# irisデータセットをサンプルデータとして使用
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
# trainとtestに分けてみる。
X_train, X_test, Y_train, Y_test = train_test_split(df.drop("target", axis=1), df.target,train_size=0.8)通常の標準化作業
# StandardScaler読み込み
from sklearn.preprocessing import StandardScaler
# 標準化したいカラムを用意
scaling_columns = ["sepal length (cm)", "sepal width (cm)", "petal length (cm)", "petal width (cm)"]
### 通常の標準化###
# trainと言うDataFrameにfit
sc = StandardScaler().fit(X_train[scaling_columns])
# 標準化したカラムのみ元のDataFrameに戻す
scaled_train = pd.DataFrame(sc.transform(X_train[scaling_columns]), columns=scaling_columns, index=X_train.index)
X_train.update(scaled_train)
# 例えば本番データの変換を見据えて、この度のStandardScalerを保存しておくこともできます。
from joblib import dump
dump(sc, "StandardScaler.bin", compress=True)標準化を元に戻す
# 保存したStandardScalerを読み込み
from joblib import load
sc = load("./StandardScaler.bin")
# 標準化したカラムのみ標準化を戻し、元のDataFrameに戻す
rescaled_train = pd.DataFrame(sc.inverse_transform(X_train[scaling_columns]), columns=scaling_columns, index=X_train.index)
X_train.update(rescaled_train)標準化を戻す必要について
標準化を元に戻すシーンは非常に限られているのではというのが2年目を迎えた私の印象です。
ここは私の初心者ならではの想像ですが、おそらく回帰問題で目的変数も標準化してしまっていて、予測値が標準化されているから戻したいということになっていないかなと思っています。
回帰問題の目的変数の標準化は必要がありません。
もちろん分類問題も必要ありません。
ぜひ以下のStackExchangeを参考にしてください。
Is it necessary to scale the target value in addition to scaling features for regression analysis?
I'm building regression models. As a preprocessing step, I scale my feature values to have mean 0 and standard deviation 1. Is it necessary to normalize the t...
stats.stackexchange.com
強いて言えば、RMSE等の数字が標準化している時と比べて大きくなると思います。
でもそれは標準化した時のRMSE値とは比較できるものではありません。
ただコンペではRMSEの大小で比べるため、ネット上のサンプルを見ても全ての変数を標準化してるものが多いのかななんて思っています。
まとめ
Scikit-LearnのStandardScalerを使った標準化の戻し方をお話しさせていただきました。
加えて保存/読み出しの方法も書いてあります。
本番予測時には、予測データではなく、手元にあるデータから得られた標準偏差と平均で予測データを標準化する必要があるので、保存しておくと楽なんです!
皆さんの参考になればと思います。
それでは!
コメント