相関が高すぎる列が説明変数に残っていると多重共線性を引き起こすと言われています。
また二つのカラムで相関が高いということは、その変数が持っている意味がほぼ同じ内容の可能性もあります。(どちらかで十分)
無駄な説明変数は除いたほうが分析もシンプルになって良いです。
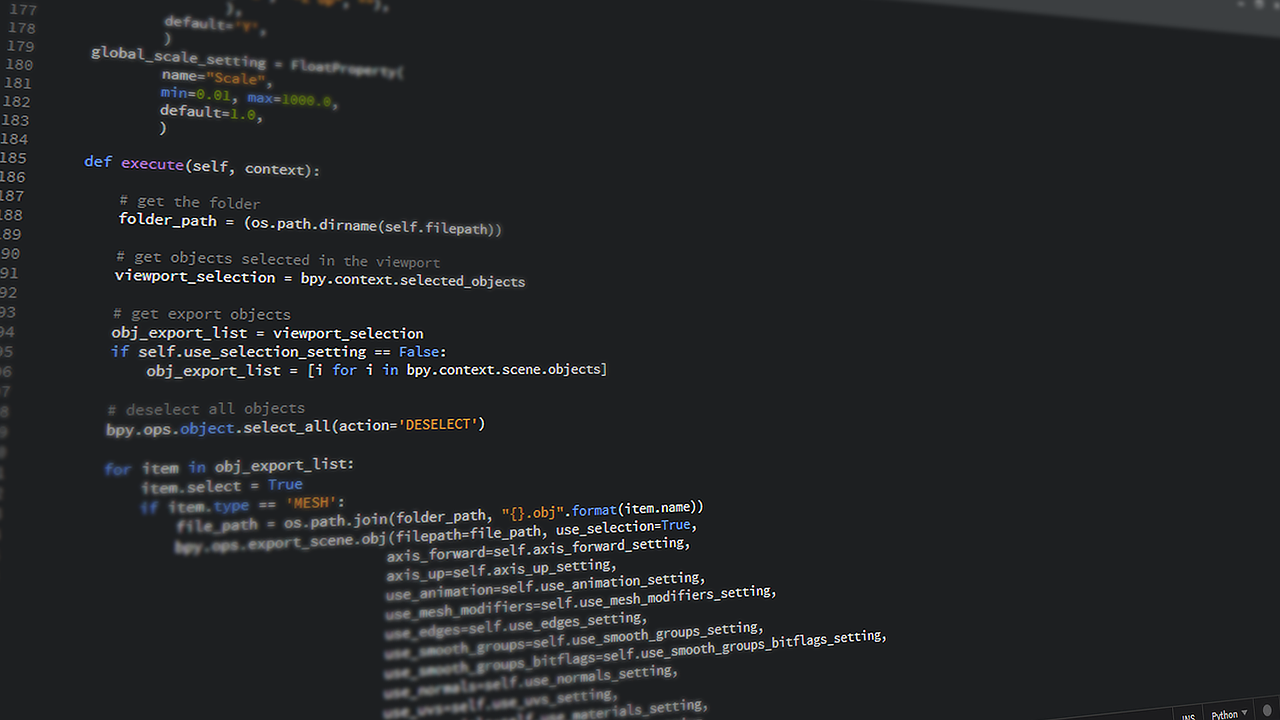
Pythonコード
# 特徴量のみ
feature_columns = ["a", "b", "c"]
# 相関係数が高いカラムを入れる変数
high_corr_features = set()
# カラム同士の相関係数を計算。
corr = df[feature_columns].corr()
# カラム同士の相関係数を1ペアずつ見ていく
for i in range(len(corr)):
for j in range(i):
# 相関係数が+-0.85より大きい場合
if abs(corr.iloc[i, j]) > 0.85:
col_name = corr.columns[i]
# 削除対象
high_corr_features.add(col_name)
# 相関が高かった列を元のDataFrameから削除
for col in high_corr_features:
if col in df.columns:
df.drop(col, axis=1, inplace=True)それでは!
コメント