不均衡データを学習させる際に、まず思いつくのがデータの水増しです。
ただし、水増しをすることによってデータがメモリに乗らないといったことが起こることもあります。
そう言った場合に重み付けを行うことでデータの水増しを行うことなく不均衡データに対応することができます。
重み付けとは、目的関数の誤差にラベルごとのペナルティを加えることで不均衡データでも均衡データと同じように目的関数を最適化させる方法です。
以下にTensorflow Estimator、XGBoostとLightGBMの重み付けのサンプルを紹介します。
また、重み付けにはscikit-learnのclass_weightモジュールを使用します。
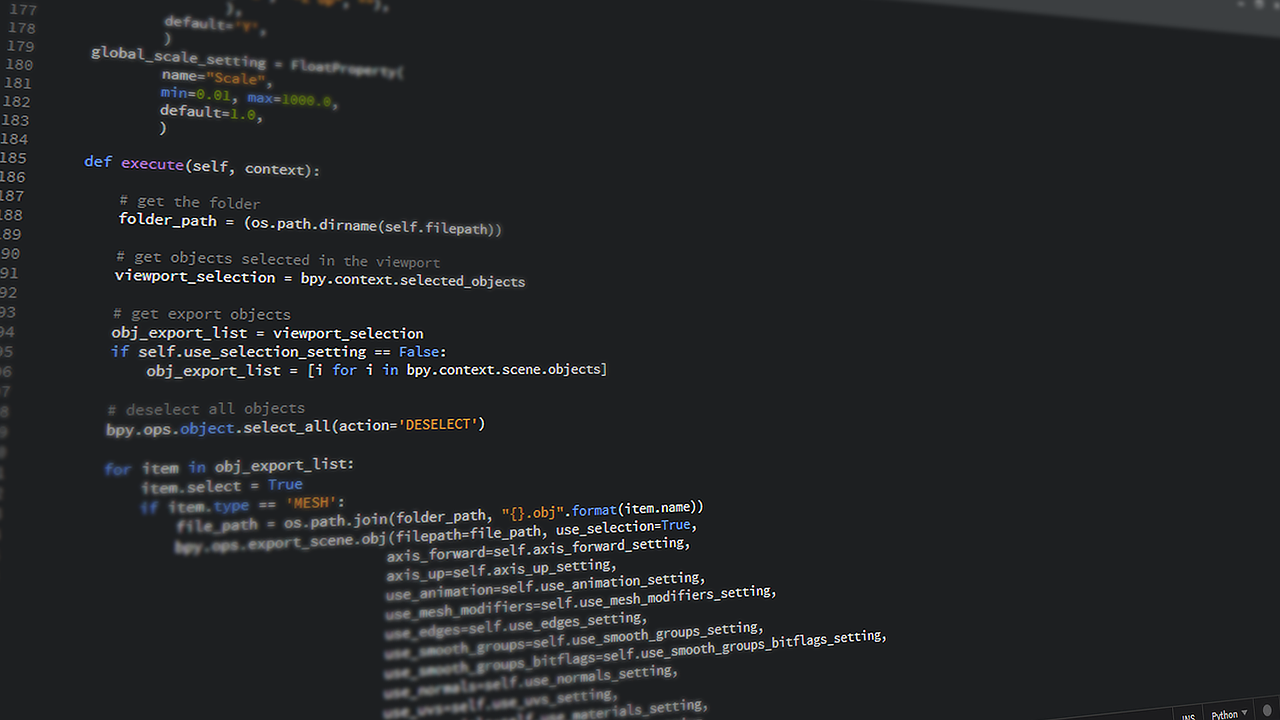
Pythonソース
XGBoostの場合
from sklearn.utils.class_weight import compute_sample_weight
# ....
# 交差検証を想定
## train
weight_train = compute_sample_weight(class_weight='balanced', y=x_train.Target) # 1:1で重み付け
# ....
# モデルの宣言の中で(trainの場合のみ。testの場合は設定する必要なし)
xgb_classifier.fit(X_train, y_train, sample_weight=weight_train)
# ....LightGBMの場合
from sklearn.utils.class_weight import compute_sample_weight
# Datasetへ変換時に引数weightにcompute_sample_weightの結果を渡す。
trn_data = lgb.Dataset(X_train, label=y_train.Target, weight=compute_sample_weight(class_weight='balanced', y=y_train.Target).astype('float32'))
# 検証データには全て1になっているデータを渡す。
val_data = lgb.Dataset(X_test, label=y_test.Target, weight=np.ones(len(X_test)).astype('float32'))
clf = lgb.train(
model_params, trn_data, **fit_params,
valid_sets=[trn_data, val_data],
fobj=fobj, feval=feval別アプローチ:データ拡張で不均衡を解消
重み付け以外の不均衡データ対策の1つ、データ拡張による不均衡の解消方法ついてはこちらを参考ください。
まとめ
メモリを節約して不均衡データに対応する方法の1つとして、重み付けを紹介しました。
ダウンサンプリングもメモリを節約した対応になりますが、モデルが使用するデータが少なくなる為学習がうまくいかないこともあります。
そう言った場合に一度試してみてください。
それでは!
コメント