みなさんこんにちは!
今回は、不均衡データへの対策の1つであるデータ拡張について話したいと思います。
数が少ない方のラベルデータ拡張をすることで、まず不均衡が解消されることはもちろん、データが増えるので精度の向上も見込めます。
データ拡張って言われると「難しいんでしょ?」という印象ですが、SMOTEのデータ拡張は簡単にできます。
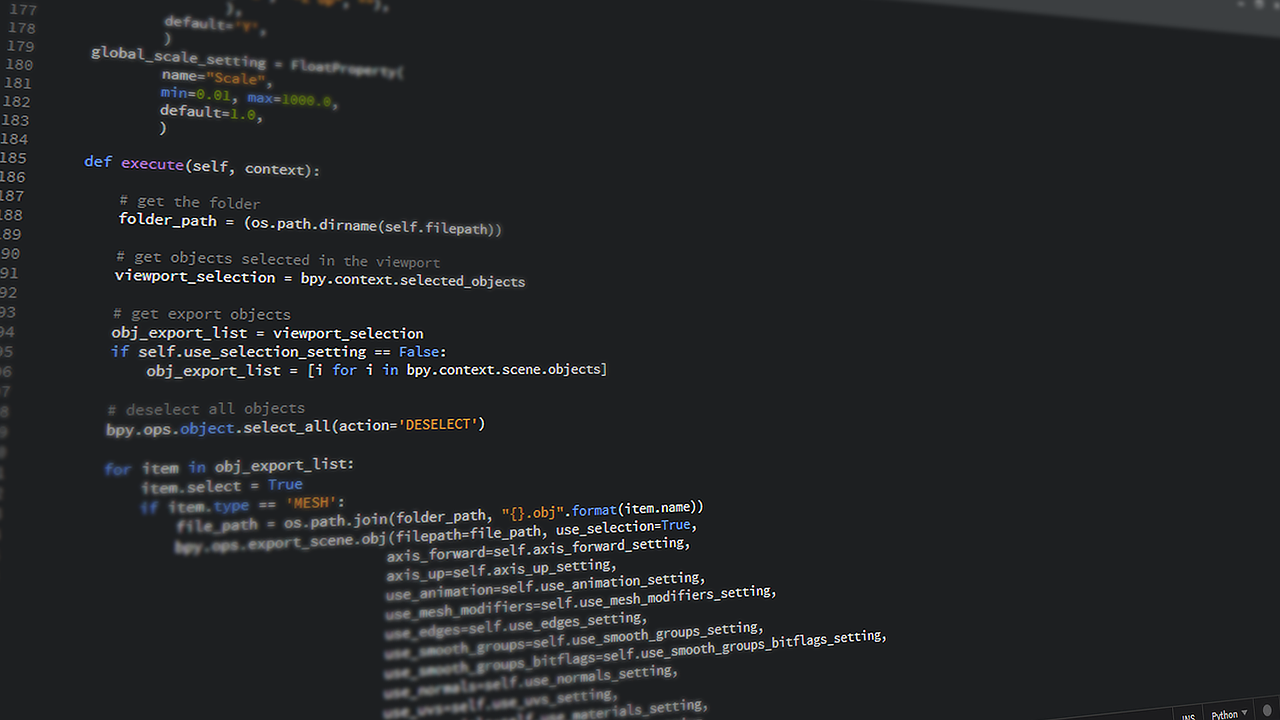
早速ですがコードを紹介したいと思います。
インストールコマンド
pip install imbalanced-learnでインストールできます。
Pythonコード
カテゴリ変数なし
# ライブラリ読み込み
from imblearn.over_sampling import SMOTE
# ....省略
# 交差検証やホールドアウトのtrainデータに対してのみ拡張する
# Target列に答えがあるクラス分類のデータだとする
train = df
# 説明変数と目的変数に分ける
x_train = train.drop("Target", axis=1)
y_train = train.Target
# k_neighborsのdefaultは5、数値チューニングで精度が変動します。
smote = SMOTE(k_neighbors=5)
# 自動で少ない方を同じ数に拡張してくれる。(全ての列がint/floatである必要あり。)
x_train, y_train = smote.fit_resample(x_train, y_train)
# ....省略
# 以降学習のコードがあるイメージカテゴリ変数あり
# カテゴリ変数がある場合
from imblearn.over_sampling import SMOTENC
# ....省略
# 交差検証やホールドアウトのtrainデータに対してのみ拡張する
# Target列に答えがあるクラス分類のデータだとする
train = df
# 説明変数と目的変数に分ける
x_train = train.drop("Target", axis=1)
y_train = train.Target
# カテゴリ変数の列indexを取得(書き方がスマートでなくてすみません。)
category_index = []
cat_columns = ["cat1", "cat2"] # カテゴリ列名
for col in cat_columns:
category_index.append(x_train.columns.get_loc(col))
# 使い方はほぼ一緒。
# k_neighborsのdefaultは5、数値チューニングで精度が変動します。
smotenc = SMOTENC(k_neighbors=10, categorical_features=category_index)
# 自動で少ない方を同じ数に拡張してくれる。(全ての列がint/floatである必要あり。)
x_train, y_train = smotenc.fit_resample(x_train, y_train)
# ....省略
# 以降学習のコードがあるイメージ
注意
学習データにのみデータ拡張を行い、検証データ、テストデータに対してはデータ拡張を行なってはいけません。
なぜなら実際のデータの比率に対しての精度を見て評価を行わないといけないからです。
つまりtrain_test_splitを行なったなら、trainにのみ使用してください!
ダミーデータで評価するつもりですか?
検証データ/テストデータには触れてはいけません。
まとめ
SMOTEを使うと構造化データはかなり簡単にデータ拡張を行うことができます。
原理は、KNNを用いて似ているデータを引数であるn_neighbors分だけ見つけたらその平均をとって拡張データとする、ということだそうです。
データが増える為精度向上が見込めますが、デメリットとしては、データ量が大きい場合はさらにデータが増えてしまうことです。もしそれで作業に影響が出る場合は別の対策が必要です。
参考になればと思います。
それでは!
コメント