みなさんこんにちは。
久しぶりの投稿になってしまいましたが、いかがお過ごしでしょうか。
本日はscipyで確率分布からとある点の確率を求める方法を共有したいと思います。
結論: CDF関数を使いより右側のポイントのCDFから左側のポイントのCDFを引き算する
import scipy.stats
# 平均0、分散1の正規分布を作成
normal_distribution = stats.norm(0, 1)
# -1〜1(1標準偏差分)の範囲の値を取る確率は、以下のようにCDF関数を使って、より右側の点(この場合は1)のCDF:累積分布関数からより左側の点(この場合は-1)のCDFの値を引いて求めることができます。
normal_distribution.cdf(1) - normal_distribution.cdf(-1)
# →0.6826894921370859確率を求める関数はpdf()関数??
こちらのStackOverflowでは、「平均と標準偏差が分かっている正規分布からどのように確率を計算したら良いでしょうか」という質問ですが、回答を見ると「pdf()関数を使って確率を得る」というものが1番のUpVoteを得ています。
しかし、厳密には、PDF関数は確率を求める関数ではありません。
PDF: 確率密度関数とは
確率密度関数とは、

確率密度は定義域内でのXの値の「相対的な出やすさ」を表すものです。
https://bellcurve.jp/statistics/course/6602.html
とあるように、確率ではないものを表します。
具体的には、例えばとある点の確率密度が1.2であるとします。
(注:確率ではないので1を超えることもあります。)
このとき、この点における確率密度が1.2であるという意味は、その点が出現する出やすさがその点を除いた他の点や区間と比べて、1.2倍大きいということを意味します。
ちなみに、離散値の場合はPDFを使って得られる値は確率になります。
連続確率分布の場合に確率を求めるには”1点”ではなく”範囲”が必要
連続値の確率分布の場合は、とある点の確率は0になります。
連続確率分布として一様分布[-1, 1]を考えると[-1, 1]を取る確率は100%ですが、区間の確率はその区間の長さを全体の範囲で割ったものになります。そのため、点を絞り込むにつれて([-1, -0.99…])、その点を含む区間の長さは無限に小さくなり、その点の確率は必ず0となります。
それ故に、確率を求める場合は範囲を指定する必要があります。
連続確率分布の範囲の確率を求めるにはCDF関数を使う
累積分布関数(CDF)とは
累積分布関数(CDF)とは、確率分布において、ある点を境界としたその点以前の確率を表すものです。
たとえば、平均0分散1の正規分布([-∞, ∞]を取る)があった場合、CDF(0)を求めるとそれは[-∞, 0]の確率を求めることになります。
正規分布は平均値を軸に左右対称なので0.5、つまり区間[-∞, 0]を取る確率は50%という結果になりますね。
累積分布関数(CDF)を使って範囲の確率を求める
この累積分布関数を使えば、確率分布の特定の点や区間に含まれる確率を求めることができます。たとえば、区間[a, b] の確率は次のようになります。
もしも a > bである場合、
CDF(a) - CDF(b)
と計算すれば、結果、区間[a, b]の確率を得ることができます。
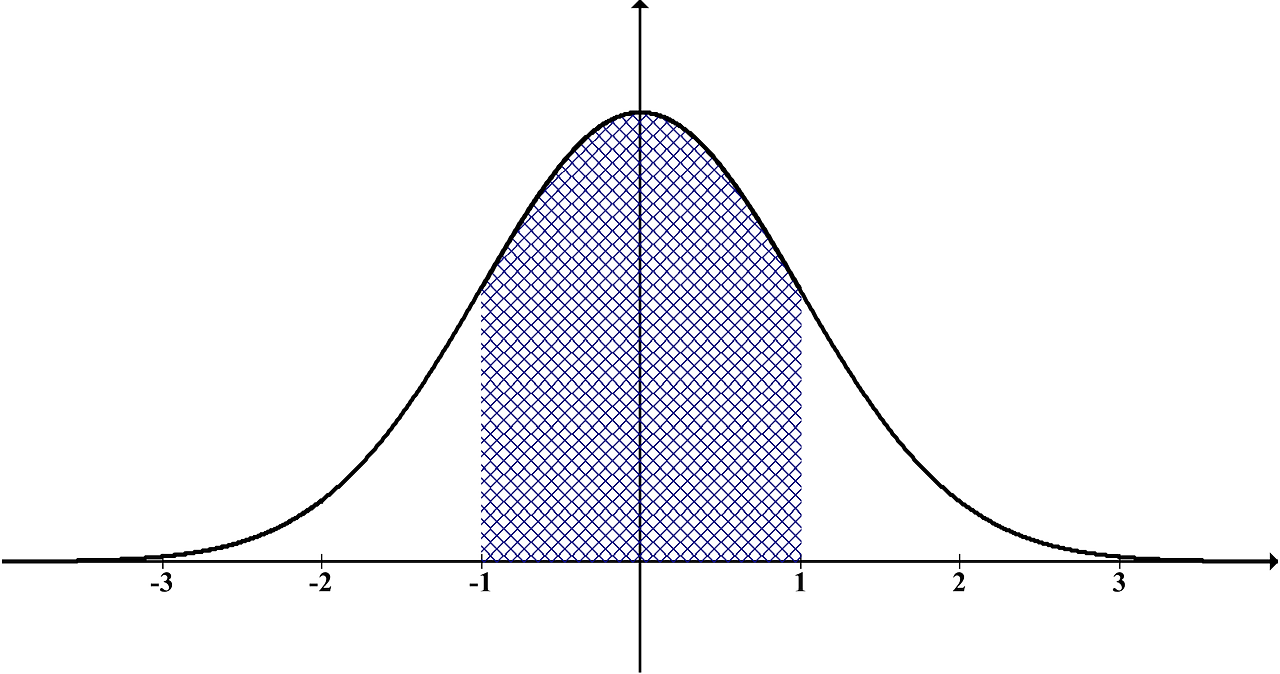
別の例として、正規分布の±1標準偏差の範囲は全体の約68%を含むとよく聞くと思いますが、
これについても、同じく平均0分散1の正規分布を仮定し実際に計算を行ってみると、
import scipy.stats
# 平均0、分散1の正規分布を作成
normal_distribution = stats.norm(0, 1)
# -1〜1(1標準偏差分)の範囲の値を取る確率は、以下のようにCDF関数を使って、より右側の点(この場合は1)のCDF:累積分布関数からより左側の点(この場合は-1)のCDFの値を引いて求めることができます。
normal_distribution.cdf(1) - normal_distribution.cdf(-1)上記コードの出力は
0.6826894921370859 ( ≒ 68%)
になり、この計算方法が正しいことがわかります。
まとめ
StackOverflowでも一番upvoteが多くなってしまうほど誤解されているPDF関数の使い方。
正しく理解して使っていきたいものです。
それでは!

コメント